
Tópico 15 – Intervalos de Confiança e Bootstrapping
Como na prática em Ciência de Dados raramente temos acesso à população inteira, na maior parte das vezes realizamos a inferência desejada com base em uma amostra. Porém, uma amostra nos possibilita ter apenas uma estimativa, e muitas vezes ficamos incertos sobre o quão precisa de fato é essa estimativa. Nessa aula, vamos aprender como quantificar a incerteza sobre nossas estimativas e como aplicar uma técnica pioneira que nos permite, com base em uma única amostra, simular diferentes cenários possíveis para nossas estimativas.
Resultados Esperados
- Entender o papel das distribuições amostrais na quantificação de incerteza sobre nossas estimativas.
- Aprender sobre as potencialidades do bootstrap, e aprender como operacionalizá-lo na prática.
- Introduzir as noções de percentis e de intervalos de confiança nesse contexto.
Material Adaptado do DSC10 (UCSD)
#In:
# Imports for this lesson.
import numpy as np
import pandas as pd
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
# Animations
from IPython.display import display, IFrame
def show_bootstrapping_slides():
src = "https://docs.google.com/presentation/d/e/2PACX-1vS_iYHJYXSVMMZ-YQVFwMEFR6EFN3FDSAvaMyUm-YJfLQgRMTHm3vI-wWJJ5999eFJq70nWp2hyItZg/embed?start=false&loop=false&delayms=3000&rm=minimal"
width = 960
height = 509
display(IFrame(src, width, height))
Recapitulando: Inferência Estatística
Salários dos funcionários públicos da cidade de San Diego
Os salários de todos os funcionários públicos da cidade de San Diego estão disponíveis publicamente. Nesse exemplo, estamos utilizando a base de dados mais recente (de 2022).
#In:
population = pd.read_csv('https://raw.githubusercontent.com/flaviovdf/fcd/master/assets/15-Bootstrapping/data/2022_salaries.csv')
population
| Year | EmployerType | EmployerName | DepartmentOrSubdivision | Position | ElectedOfficial | Judicial | OtherPositions | MinPositionSalary | MaxPositionSalary | ... | HealthDentalVision | TotalRetirementAndHealthContribution | PensionFormula | EmployerURL | EmployerPopulation | LastUpdatedDate | EmployerCounty | SpecialDistrictActivities | IncludesUnfundedLiability | SpecialDistrictType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022 | City | San Diego | Police | Police Officer II | False | False | NaN | 87256 | 105435 | ... | 7532 | 27561 | 3.0% @ 50 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 1 | 2022 | City | San Diego | Police | Police Sergeant | False | False | NaN | 105872 | 128003 | ... | 19000 | 23508 | 3.0% @ 50 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 2 | 2022 | City | San Diego | Fire-Rescue | Fire Engineer | False | False | NaN | 69389 | 83886 | ... | 20750 | 42217 | 3.0% @ 50 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 3 | 2022 | City | San Diego | Retirement | Retirement Administrator | False | False | NaN | 106371 | 424736 | ... | 0 | 37792 | 1.0% @ 55 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 4 | 2022 | City | San Diego | Police | Police Sergeant | False | False | NaN | 105872 | 128003 | ... | 17812 | 39604 | 3.0% @ 50 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12824 | 2022 | City | San Diego | Library | Assistant Management Analyst | False | False | NaN | 54434 | 66144 | ... | 0 | 2 | NaN | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 12825 | 2022 | City | San Diego | Police | Word Processing Operator | False | False | NaN | 38189 | 45947 | ... | 0 | 0 | NaN | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 12826 | 2022 | City | San Diego | Public Utilities | Cashier | False | False | NaN | 36712 | 44179 | ... | 0 | 0 | 1.0% @ 55 | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 12827 | 2022 | City | San Diego | Police | Police Officer II | False | False | NaN | 87256 | 105435 | ... | 0 | 0 | NaN | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
| 12828 | 2022 | City | San Diego | Police | Police Dispatcher | False | False | NaN | 58115 | 70075 | ... | 0 | 0 | NaN | www.sandiego.gov | 1368395 | 06/27/2023 | San Diego | NaN | False | NaN |
12829 rows × 29 columns
Quando trabalhamos com um base de dados com um número grande de colunas, não conseguimos visualizá-las todas ao mesmo tempo. Nesses casos, é sempre uma boa ideia analisarmos os nomes das colunas.
#In:
population.columns
Index(['Year', 'EmployerType', 'EmployerName', 'DepartmentOrSubdivision',
'Position', 'ElectedOfficial', 'Judicial', 'OtherPositions',
'MinPositionSalary', 'MaxPositionSalary', 'ReportedBaseWage',
'RegularPay', 'OvertimePay', 'LumpSumPay', 'OtherPay', 'TotalWages',
'DefinedBenefitPlanContribution', 'EmployeesRetirementCostCovered',
'DeferredCompensationPlan', 'HealthDentalVision',
'TotalRetirementAndHealthContribution', 'PensionFormula', 'EmployerURL',
'EmployerPopulation', 'LastUpdatedDate', 'EmployerCounty',
'SpecialDistrictActivities', 'IncludesUnfundedLiability',
'SpecialDistrictType'],
dtype='object')
Como aqui estamos interessados apenas nos salários totais ('TotalWages'), selecionaremos (com get) apenas essa coluna.
#In:
population = population.get(['TotalWages'])
population
| TotalWages | |
|---|---|
| 0 | 384909 |
| 1 | 381566 |
| 2 | 350013 |
| 3 | 347755 |
| 4 | 345113 |
| ... | ... |
| 12824 | 29 |
| 12825 | 8 |
| 12826 | 6 |
| 12827 | 4 |
| 12828 | 2 |
12829 rows × 1 columns
#In:
population.plot(kind='hist', bins=np.arange(0, 400000, 10000), density=True, ec='w', figsize=(10, 5),
title='Distribuição dos Salários Totais dos Funcionários Públicos da cidade de San Diego em 2022')
plt.ylabel('Frequência');

Salário mediano
- Podemos utilizar a função
.median()para calcular o salário mediano de todos os funcionários públicos da cidade de San Diego. - Note que, como temos a população inteira disponível, essa mediana é um parâmetro, i.e. não-aleatória.
#In:
population_median = population.get('TotalWages').median()
population_median
78136.0
Na prática, porém…
- Na prática, o processo de entrevistar toda a população (no caso mais de 12,000 funcionários) é caro e pode consumir muito tempo.
- Além disso, muitas vezes é impossível entrevistar todos os indivíduos da população.
- O que fazemos então é aferir os salários com base em uma amostra aleatória (nesse exemplo tomamos $n = 500$).
Revisão da terminologia
O DataFrame completo de salários, i.e.
population.get(['TotalWages']), é a nossa população.Nós observamos uma amostra de tamanho $n = 500$ dessa população.
Queremos determinar a mediana populacional (que é um parâmetro), mas como não temos acesso à população completa, utilizaremos a mediana amostral (que é uma estatística) como uma estimativa desse parâmetro.
Nesse processo, esperamos que a mediana amostral seja próxima da mediana populacional.
A mediana amostral
Vamos amostrar 500 funcionários aleatoriamente. Para fazer isso, podemos utilizar o método .sample.
#In:
np.random.seed(38) # Magic to ensure that we get the same results every time this code is run.
# Take a sample of size 500.
my_sample = population.sample(500)
my_sample
| TotalWages | |
|---|---|
| 10301 | 27866 |
| 6913 | 71861 |
| 5163 | 91843 |
| 6445 | 77727 |
| 5861 | 84770 |
| ... | ... |
| 12493 | 1935 |
| 7020 | 70557 |
| 3002 | 121209 |
| 3718 | 109709 |
| 2394 | 131409 |
500 rows × 1 columns
Nesse notebook, não vamos mais modificar my_sample, então esse DataFrame vai sempre se referir à essa amostra em particular.
#In:
# Compute the sample median.
sample_median = my_sample.get('TotalWages').median()
sample_median
76237.0
O quão confiantes estamos que essa é uma boa estimativa?
Nossa estimativa é função da amostra aleatória particular
my_sample. Se tívessemos coletado outra amostra, a estimativa poderia ter sido diferente.Agora, o quão diferente nossa estimativa poderia ter sido? Nosssa confiança na estimativa depende fundamentalmente da resposta à essa pergunta.
The sample median is a random number. It comes from some distribution, which we don’t know.
Se conhecéssmos a distribuição verdadeira da mediana amostral (i.e. a distribuição amostral), essa distribuição nos ajudaria a responder essa pergunta.
- Distribuições mais “estreitas” (i.e. com baixa variabilidade/dispersão) $\Rightarrow$ nossa estimativa em geral não teria sido tão diferente.
- Distribuições mais “largas” (i.e. com alta variabilidade/dispersão) $\Rightarrow$ nossa estimativa em geral teria sido bem diferente.
Uma abordagem ineficiente
- Uma ideia natural aqui então seria: coletar repetidas amostras de tamanho $n = 500$ da população e calcular as medianas amostrais de cada uma.
- Foi examente isso o que fizemos na aula anterior, quando calculamos a distribuição empírica das médias amostrais dos atrasos de vôos (como aproximação para a distribuição amostral).
#In:
sample_medians = np.array([])
for i in np.arange(1000):
median = population.sample(500).get('TotalWages').median()
sample_medians = np.append(sample_medians, median)
sample_medians
array([81686.5, 79641. , 75592. , 79469.5, 77175. , 75526.5, 77413. ,
86007. , 78891.5, 71640.5, 78253. , 83384. , 82162. , 74003.5,
79478. , 79985.5, 75580.5, 84105.5, 84890.5, 81649.5, 78085. ,
78449. , 75220. , 74996. , 74392. , 78017.5, 83398.5, 78928. ,
83277. , 73590. , 73691. , 84165. , 74246.5, 83854.5, 74342. ,
79689. , 81256. , 80983.5, 79579.5, 78033.5, 75918. , 76480. ,
76747.5, 78460.5, 77018. , 85621. , 79800. , 78172.5, 80487.5,
80164.5, 75039. , 81065.5, 84117. , 77577. , 74250.5, 79980. ,
75246. , 80619.5, 76118.5, 75835. , 79458.5, 79705.5, 83076.5,
79501.5, 78588. , 75554.5, 83264. , 79714.5, 82792.5, 75455. ,
77597.5, 71865. , 70303. , 77472. , 77054.5, 79156.5, 78637. ,
74680.5, 76653. , 69339. , 72018. , 75271.5, 77726. , 77975. ,
72222.5, 78741.5, 72568. , 74245.5, 79069. , 80487. , 71996. ,
78742.5, 77119.5, 80751.5, 81273.5, 79862.5, 72562.5, 84078.5,
73879. , 76557. , 72682. , 77076.5, 79239.5, 79517. , 82193.5,
77431. , 70932. , 74613.5, 78831. , 75946. , 75495.5, 80395.5,
77796. , 74833.5, 77458. , 78243.5, 79289. , 81876. , 72535.5,
71646. , 77956. , 83139.5, 71294. , 70114.5, 74787. , 81019.5,
76827.5, 75640.5, 73494. , 77547.5, 81855.5, 68920. , 82074.5,
73882.5, 78614. , 74359.5, 84428.5, 75968.5, 80128. , 69545.5,
83167. , 80024.5, 83176. , 76921. , 82364. , 80495.5, 81630. ,
85638. , 75693. , 78960.5, 77763. , 79041. , 77943.5, 75997.5,
80157.5, 79342. , 79488.5, 77416.5, 74128.5, 81461. , 83135.5,
71046.5, 75724. , 80933.5, 75349.5, 74694. , 81216. , 81706. ,
74374. , 76528.5, 81589.5, 81040.5, 74758.5, 75366.5, 84609.5,
77164.5, 75171.5, 81737. , 82023.5, 81525.5, 76760.5, 76718. ,
81798. , 81694. , 83348.5, 83742.5, 80448.5, 71706.5, 87240. ,
79233. , 78726.5, 84864. , 82489.5, 69132. , 76921. , 74693. ,
77497. , 82245. , 76929. , 82289.5, 82602. , 78248. , 77429. ,
76942.5, 77404.5, 73540. , 84142. , 73575.5, 79342. , 78861.5,
76935. , 74801.5, 84408.5, 75229. , 78856. , 77579. , 76672. ,
78606. , 74782. , 80454.5, 83855. , 74045. , 83553. , 79733.5,
77721.5, 78361.5, 78675. , 75052. , 81042.5, 78927.5, 82075.5,
76420. , 81904. , 80960.5, 72084. , 74809.5, 74983. , 73501. ,
76880.5, 77680.5, 77717.5, 78650. , 75078. , 84003. , 75911. ,
80807.5, 73770. , 76208. , 80126.5, 79417. , 72807.5, 80614. ,
80703. , 82781.5, 73035.5, 77849. , 78835.5, 79770.5, 75800. ,
78902.5, 71730.5, 78574.5, 79914. , 78546. , 81252. , 78895. ,
76408.5, 76836. , 75829. , 78876.5, 76039.5, 83185.5, 76461. ,
77746.5, 76935.5, 72213.5, 79273. , 70648.5, 75613.5, 81665. ,
79460.5, 71826. , 74017. , 80131. , 80244. , 75232.5, 83491.5,
68415. , 84019.5, 75704.5, 78566.5, 74558. , 76919.5, 78432. ,
75116. , 74863.5, 81388.5, 77455.5, 77682.5, 71703. , 75341. ,
81324.5, 78264. , 78906.5, 75887. , 82782.5, 82815. , 81453. ,
69057. , 71480.5, 77317.5, 77938.5, 82239.5, 78036. , 78617. ,
75798.5, 80051.5, 80816.5, 88310.5, 78567. , 78756. , 74623. ,
75954. , 76968. , 77579. , 84591.5, 84261.5, 80683. , 77013.5,
77744.5, 78180.5, 80567.5, 78763. , 76840. , 79249.5, 84500.5,
77766. , 72200. , 79731. , 80228. , 77778.5, 72206.5, 75850.5,
72543.5, 79963. , 83103.5, 77943. , 77522. , 74045.5, 80593. ,
74884. , 79745.5, 80117. , 82802. , 83697.5, 72850. , 80681.5,
71934.5, 84493.5, 78833.5, 81267. , 82178.5, 75454.5, 80788. ,
80567. , 74488. , 74247.5, 76683.5, 76537.5, 79780.5, 80744. ,
77620.5, 82176.5, 77162. , 79903. , 77549.5, 76925. , 77380. ,
77348. , 73850.5, 76949. , 84097.5, 78746.5, 80269. , 81154. ,
70930. , 79193. , 82696.5, 78686. , 77888. , 80735.5, 79188.5,
74245.5, 77974. , 80200.5, 82211.5, 78845.5, 80431. , 84430. ,
82184.5, 76403. , 78248. , 81895.5, 74061. , 74635. , 75796. ,
73580.5, 81111. , 69685.5, 73448.5, 81500. , 76684.5, 75231.5,
80795. , 77869.5, 75576.5, 81394. , 79671. , 78682. , 74716.5,
77407. , 73879.5, 74448. , 71359.5, 75977. , 80889.5, 73801.5,
83273.5, 78802.5, 77848. , 78835.5, 74838.5, 77393.5, 75555.5,
78857. , 78688.5, 77512.5, 78746. , 77888.5, 76401.5, 78892. ,
74047.5, 80324. , 78537. , 73950.5, 84456. , 73304.5, 74470. ,
81718. , 71971.5, 74762.5, 75394.5, 76611. , 82254.5, 73577.5,
76921. , 80105.5, 73460.5, 80033.5, 79662. , 80075.5, 74939.5,
77552. , 71954. , 75868. , 77888. , 75604.5, 72305. , 81605. ,
83205. , 80582.5, 79588.5, 80002.5, 83626.5, 75208.5, 79817. ,
77209.5, 78999.5, 80861. , 74925. , 75154. , 80927.5, 77175.5,
79166.5, 79229. , 77766. , 81001.5, 80306. , 77187. , 75566. ,
76451.5, 78741.5, 73787. , 79472.5, 73029. , 80198.5, 80096. ,
76391. , 80564. , 75221.5, 80977. , 80540.5, 77430.5, 79752.5,
72007. , 80290.5, 82557.5, 79630.5, 78109. , 78384.5, 77623. ,
78215. , 76082.5, 75386.5, 81363.5, 83956. , 72098. , 74552. ,
80070.5, 77886. , 75118.5, 71308. , 86353. , 81871. , 75354. ,
72534.5, 86076. , 81434. , 84891.5, 78506. , 80362.5, 76990.5,
74712.5, 80928. , 74566.5, 80198. , 81212. , 79819. , 77500. ,
73309.5, 84413.5, 83106.5, 78638.5, 83016. , 77816.5, 81656.5,
82185. , 76172. , 79255.5, 82074. , 80206.5, 77142.5, 81225.5,
75414.5, 78089.5, 79766. , 79553. , 74744.5, 81678. , 76972. ,
78392. , 74515. , 75116. , 74448.5, 81855.5, 77883. , 80714. ,
79828.5, 85025. , 81869. , 73984. , 77344.5, 75950.5, 83517.5,
71204.5, 77038. , 84589.5, 81452. , 80364. , 75307.5, 80437.5,
82489.5, 78090. , 75006. , 80812. , 77302. , 74909.5, 76300. ,
74561.5, 83800.5, 82033. , 78818.5, 73610.5, 79565.5, 82255.5,
78899.5, 71997.5, 79909. , 82125. , 76996.5, 79301.5, 76000.5,
77454. , 74959. , 77158.5, 80737.5, 70709.5, 75509. , 76168. ,
80306.5, 73676.5, 74587. , 80908.5, 70950.5, 78063.5, 78348. ,
76171. , 85174.5, 80731.5, 78928. , 86958.5, 81809. , 81582. ,
83057. , 77454.5, 81791. , 73889.5, 77585.5, 83989. , 73341.5,
80388.5, 78336. , 81592.5, 82801.5, 77740. , 77043.5, 78243.5,
80232.5, 80348.5, 78770. , 71825.5, 83531.5, 79759.5, 74647. ,
68879.5, 78659. , 78301. , 79648.5, 76788.5, 77353. , 78071.5,
77324. , 77497.5, 68073.5, 77738. , 77178.5, 75130. , 75453.5,
74970.5, 75402. , 74063. , 80615.5, 75425. , 80500.5, 79793. ,
76989.5, 76616.5, 81276. , 78056.5, 75668.5, 74452.5, 78893.5,
79957. , 70867. , 77439. , 70718.5, 78870. , 82847.5, 82238.5,
83467.5, 72673. , 77036.5, 74256.5, 78136. , 76107.5, 72592.5,
80102. , 79350.5, 79555.5, 74165.5, 81517.5, 77952. , 77245.5,
77610. , 82411.5, 75764. , 71260. , 71925. , 79402. , 75910. ,
76900.5, 77919. , 78070. , 79375. , 73740.5, 77065. , 70675.5,
77644. , 80105.5, 76508. , 78744.5, 70614.5, 79404.5, 84781. ,
80279.5, 80339. , 79433. , 85525. , 74722. , 81923. , 83215. ,
76876.5, 77427. , 80553. , 85985.5, 82196.5, 79571. , 71138. ,
76120. , 74278. , 77184. , 77123. , 76269.5, 70698. , 78279. ,
80585.5, 77102.5, 77893.5, 79434. , 76047. , 78673.5, 74121.5,
80338. , 78734. , 83201.5, 76989.5, 77453. , 75902. , 80640. ,
78193. , 79889.5, 78744.5, 81993. , 74717. , 72395.5, 81052.5,
76983. , 79323. , 81819. , 80235.5, 78721.5, 81510.5, 83405. ,
77455.5, 77378. , 75439.5, 78700.5, 74042. , 70573. , 86006. ,
77470.5, 80716. , 81947. , 81163.5, 80436.5, 77538.5, 77159. ,
76333.5, 82013.5, 73907.5, 72168. , 70869. , 78879.5, 75820. ,
85968. , 78490.5, 78553. , 83141.5, 78001. , 76856.5, 77920. ,
75956. , 83616. , 80429.5, 77287. , 69872.5, 71279.5, 78082. ,
78842.5, 81539. , 74982. , 77486. , 77916. , 76755. , 74543.5,
77549. , 73800.5, 81199.5, 73063.5, 80444. , 77325.5, 76726.5,
78081. , 76559. , 77442. , 85738. , 77104. , 81356. , 73693.5,
74583. , 75518.5, 79770.5, 80656.5, 76687.5, 74341.5, 82861. ,
75629. , 78079. , 77900.5, 80033.5, 83524. , 84216.5, 80103. ,
76000.5, 78078. , 82788.5, 75794. , 77884.5, 80853. , 73841. ,
75148.5, 75802. , 76431. , 79837.5, 75896. , 80047. , 77336. ,
80874. , 79556.5, 75073.5, 77595. , 81463. , 78041. , 79268.5,
77559. , 69928.5, 84028.5, 78569. , 73471. , 78680. , 75918.5,
75975.5, 81840. , 77891.5, 80585. , 77736.5, 74197.5, 86675.5,
80863.5, 74826. , 69192. , 75864. , 77348. , 80235. , 76185.5,
75158.5, 76221.5, 79798.5, 71188.5, 83042.5, 79977. , 78553.5,
78108.5, 75109. , 76156.5, 75960.5, 74683.5, 76524. , 75242. ,
77245. , 78692.5, 78292.5, 78091.5, 78835.5, 74628. , 84802.5,
82213. , 79211. , 81900. , 78636. , 76304. , 82187.5, 80021. ,
75433. , 76412.5, 83852. , 72805.5, 68601. , 79223. , 76835. ,
77792.5, 79335.5, 75045. , 81631.5, 70936. , 76672.5, 74863.5,
75471.5, 86055.5, 84183.5, 76955. , 77676.5, 76939.5, 75922. ,
77072. , 75182.5, 76556.5, 72948.5, 81311.5, 80436. , 75879.5,
72187.5, 74841. , 76367.5, 77234. , 72142.5, 86134. , 79695.5,
75938.5, 77850. , 72636.5, 78913.5, 80237.5, 71225.5, 75524.5,
74101.5, 73501. , 81821.5, 78190.5, 74130. , 79747. , 82361.5,
81312. , 73549.5, 81104. , 84750.5, 76788.5, 73980. , 74690.5,
83653.5, 73816.5, 78730. , 76431. , 79736. , 77353. , 74097. ,
78811. , 75551.5, 79520. , 79751. , 79290.5, 83143.5, 76327. ,
75044.5, 79419. , 79561. , 82306.5, 70006.5, 81066.5, 73713. ,
83575. , 77412.5, 77173.5, 78234.5, 76457.5, 78331.5, 78003. ,
73859. , 75361.5, 77690.5, 79306.5, 73023.5, 73656.5, 73260.5,
77295. , 84928. , 80520.5, 79350. , 78826.5, 78459.5])
#In:
(pd.DataFrame()
.assign(SampleMedians=sample_medians)
.plot(kind='hist', density=True,
bins=30, ec='w', figsize=(8, 5),
title='Distribuição da Mediana Amostral de 1,000 Amostras da População\n de Tamanho $n = 500$')
)
plt.ylabel("Frequência");

- Essa distribuição empírica da mediana amostral é uma aproximação para sua verdadeira distribuição amostral.
E porque essa abordagem é ineficiente?
- Amostrar repetidas vezes da mesma população muitas vezes é infactível pelas mesmas razões pelas quais não trabalhamos com a população desde o começo!
- Se pudéssemos fazer isso, porque não simplesmente coletar mais dados (i.e. uma amostra maior)?
- Ideia pioneira: se a distribuição da nossa amostra original
my_samplese parece com a distribuição populacional, podemos aproveitar esse fato para derivarmos uma boa aproximação para a distribuição amostral de interesse.
#In:
fig, ax = plt.subplots(figsize=(10, 5))
bins=np.arange(10_000, 300_000, 10_000)
population.plot(kind='hist', y='TotalWages', ax=ax, density=True, alpha=.75, bins=bins, ec='w')
my_sample.plot(kind='hist', y='TotalWages', ax=ax, density=True, alpha=.75, bins=bins, ec='w')
plt.legend(['População', '`my_sample`'])
plt.ylabel("Frequência");

Note que no histograma acima estamos comparando a distribuição populacional com a distribuição empírica de uma amostra em particular (my_sample), e não a distribuição das medianas amostrais de várias amostras como vimos até agora.
Bootstrapping 🥾
Bootstrapping
- Ideia principal: Utilizar a amostra no lugar da população.
- Assumimos aqui que a amostra “se parece” com a população.
- Logo, reamostrar da amostra, de uma certa maneira, é similar à reamostrar da própria população!
- Denominamos o conjunto de técnicas que se baseiam em reamostragens a partir da amostra de bootstrapping.
#In:
show_bootstrapping_slides()
Com reposição ou sem reposição?
Nosso objetivo quando realizamos um bootstrap é gerar uma amostra do mesmo tamanho, porém com algumas características diferentes da amostra original.
Para ilustrar esse ponto, considere um exemplo simples onde vamos reamostrar repetidas vezes sem reposição, uma amostra original igual a [1, 2, 3].
#In:
original = [1, 2, 3]
for i in np.arange(10):
resample = np.random.choice(original, 3, replace=False)
print("Resample: ", resample, " Median: ", np.median(resample))
Resample: [2 1 3] Median: 2.0
Resample: [1 2 3] Median: 2.0
Resample: [1 2 3] Median: 2.0
Resample: [3 1 2] Median: 2.0
Resample: [1 3 2] Median: 2.0
Resample: [1 3 2] Median: 2.0
Resample: [3 1 2] Median: 2.0
Resample: [3 2 1] Median: 2.0
Resample: [1 2 3] Median: 2.0
Resample: [3 2 1] Median: 2.0
- Vamos agora repetir o mesmo experimento, mas dessa vez reamostrando com reposição:
#In:
original = [1, 2, 3]
for i in np.arange(10):
resample = np.random.choice(original, 3, replace=True)
print("Resample: ", resample, " Median: ", np.median(resample))
Resample: [3 2 1] Median: 2.0
Resample: [1 1 3] Median: 1.0
Resample: [3 2 1] Median: 2.0
Resample: [1 1 2] Median: 1.0
Resample: [2 1 3] Median: 2.0
Resample: [3 3 3] Median: 3.0
Resample: [1 1 1] Median: 1.0
Resample: [2 2 3] Median: 2.0
Resample: [2 3 2] Median: 2.0
Resample: [3 3 2] Median: 3.0
- Concluímos com esse exemplo que:
- Quando amostramos sem reposição, as novas amostras (amostras bootstrap) são em um certo sentido “idênticas” à amostra original – muda se apenas a ordenação dos indivíduos.
- Como consequência, todas as suas características (isto é, estatísticas), são iguais.
- Por outro lado, quando amostramos com reposição, as amostras bootstrap em geral terão características diferentes da amostra original.
- As estatísticas calculadas nas amostras bootstrap serão em geral diferentes das calculadas na amostra original, o que nos permite aferir variabilidade das estimativas entre as amostras e/ou construir uma distribuição amostral para as estatísticas de interesse.
- Quando amostramos sem reposição, as novas amostras (amostras bootstrap) são em um certo sentido “idênticas” à amostra original – muda se apenas a ordenação dos indivíduos.
- Dessa forma, quando realizamos um bootstrap, sempre reamostramos com reposição, para garantir que as nossas amostras bootstrap possam ser diferentes da nossa amostra original.
- O bootstrap funciona então como um processo que “imita”, em um certo sentido, o ato de coletar novas amostras.
Bootstrap na amostra de salários
Conforme dito anteriormente, para realizar o bootstrap na nossa amostra basta gerar novas amostras reamostrando com reposição da nossa amostra original, my_sample.
#In:
# Note that the population DataFrame, population, doesn't appear anywhere here.
# This is all based on one sample, my_sample.
np.random.seed(38) # Magic to ensure that we get the same results every time this code is run.
n_resamples = 5000
boot_medians = np.array([])
for i in range(n_resamples):
# Resample from my_sample WITH REPLACEMENT.
resample = my_sample.sample(500, replace=True)
# Compute the median.
median = resample.get('TotalWages').median()
# Store it in our array of medians.
boot_medians = np.append(boot_medians, median)
#In:
boot_medians
array([76896. , 72945. , 73555. , ..., 74431. , 75868. , 78601.5])
Distribuição bootstrap da mediana amostral
#In:
pd.DataFrame().assign(BootstrapMedians=boot_medians).plot(kind='hist', density=True, bins=np.arange(63000, 88000, 1000), ec='w', figsize=(10, 5))
plt.scatter(population_median, 0.000004, color='blue', s=100, label='population median').set_zorder(2)
plt.legend()
plt.ylabel("Frequência");

Apenas para termos uma referência do quão boa é nossa inferência, a mediana populacional é reportada no histograma acima como um ponto azul.
Lembre porém que, na maior parte das situações, não temos acesso à essa informação!
Mas afinal, como o bootstrap nos ajuda a responder nossa pergunta original?
Lembre que, aqui, iniciamos apenas com a mediana amostral:
#In:
my_sample.get('TotalWages').median()
76237.0
Com base nessa estimativa, podemos dizer apenas que o salário mediano da população é aproximadamente \$76,237, mas não muito mais do que isso.
Em particular, não podemos afirmar nada acerca da variabilidade dessa estimativa, isto é, o quão confiantes (ou incertos!) estamos sobre esse valor.
Após realizarmos um bootstrap, porém, podemos gerar uma distribuição empírica da mediana amostral:
#In:
(pd.DataFrame()
.assign(BootstrapMedians=boot_medians)
.plot(kind='hist', density=True, bins=np.arange(63000, 88000, 1000), ec='w', figsize=(10, 5))
)
plt.legend()
plt.ylabel("Frequência");

e essa distribuição nos permite realizar afirmações do tipo
O salário mediano na população está entre \$68,000 e \$82,000.
Pergunta: Poderíamos também dizer que o salário mediano na população está entre \$70,000 e \$80,000, ou entre \$65,000 e \$85,000. Qual desses dois intervalos você reportaria?
Percentis
Definição informal
Seja $p$ um número entre 0 e 100. O $p$-ésimo percentil de um conjunto de observações é o número que é maior ou igual a $p\%$ de todos os valores do conjunto.
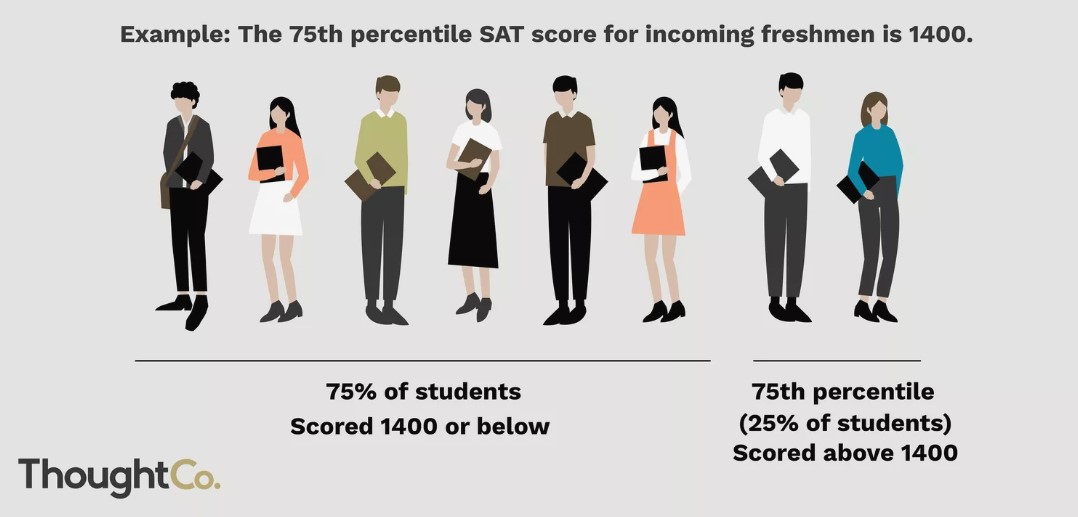
Outro exemplo: Se você está no percentil $80$ da altura de um certo conjunto de pessoas, isso significa que aproximadamente $80\%$ das pessoas desse conjunto são mais baixas que você, e que $20\%$ são mais altas.

Calculando os percentis
- O pacote
numpycontém uma função para calcular percentis,np.percentile(array, p), que retorna op-ésimo percentil dearray. - Por enquanto, não entraremos em detalhes sobre como esse valor é calculado – nos concentraremos apenas em utilizar o resultado.
- Retornaremos à esse ponto mais adiante, mas apenas para uma breve reflexão: você acha que ordenar a amostra, calcular as frequências correspondentes e encontrar o valor correspondente à frequência $p\%$ em geral é suficiente?
#In:
np.percentile([4, 6, 9, 2, 7], 50)
6.0
#In:
np.percentile([2, 4, 6, 7, 9], 50)
6.0
Intervalos de confiança
Anteriormente, geramos uma distribuição boostrap da mediana amostral:
#In:
pd.DataFrame().assign(BootstrapMedians=boot_medians).plot(kind='hist', density=True, bins=np.arange(63000, 88000, 1000), ec='w', figsize=(10, 5))
plt.scatter(population_median, 0.000004, color='blue', s=100, label='population median').set_zorder(2)
plt.legend()
plt.ylabel("Frequência");

Com base nessa distribuição, o que podemos então afirmar em termos de percentis?
Utilizando a distribuição bootstrap da mediana amostral
Nossa mediana amostral é igual a \$76,237.
Conforme mencionamos anteriormente, acreditamos que a mediana populacional seja próxima de \$76,237, mas não sabemos quão próxima.
Como quantificar então a incerteza sobre essa estimativa?
💡 Ideia: Encontrar um intervalo que contenha a maior parte (por exemplo, 95%) das medianas amostrais na distribuição bootstrap. Intervalos desse tipo são denominados de intervalos de confiança.
- Mais uma vez ressaltamos que aqui nosso principal objetivo é entender e aprender como utilizar os conceitos introduzidos – uma formalização completa do conceito de intervalo de confiança será feita em outras disciplinas mais adiante.
Definindo um intervalo de confiança
- No exemplo acima, queremos encontrar um intervalo $[x,y]$ que contenha aproximadamente 95% da área total da distribuição bootstrap. Denominamos esse intervalo de intervalo de 95% de confiança (IC95%).
- Note que um intervalo de confiança não é único – mais adiante veremos como calcular diferentes intervalos para um mesmo nível de confiança.
- Uma maneira de encontrar esse intervalo é encontrar dois pontos, $x$ e $y$, tais que:
- A área à esquerda de $x$ na distribuição bootstrap seja aproximadamente 2.5%.
- A área à direita de $y$ na distribuição bootstrap seja aproximadamente 2.5%.
- Pela definição de percentil dada acima, temos então que $x$ e $y$ são os percentis 2.5 e 97.5, respectivamente.
- Usualmente, $x$ e $y$ são respectivamente denominados limite inferior e limite superior do intervalo de confiança.
Encontrando os limites do IC95% com np.percentile
#In:
boot_medians
array([76896. , 72945. , 73555. , ..., 74431. , 75868. , 78601.5])
#In:
# Left endpoint.
left = np.percentile(boot_medians, 2.5)
left
68469.0
#In:
# Right endpoint.
right = np.percentile(boot_medians, 97.5)
right
81253.5
#In:
# Therefore, our interval is:
[left, right]
[68469.0, 81253.5]
Utilizamos códigos como esse acima o tempo todo em Ciência de Dados!
Visualizando nosso IC95%
- Vamos agora plotar o intervalo que acabamos de calcular no histograma anterior.
- Lembre que, pela definição do IC95%, que 95% das medianas da distribuição bootstrap estão contidas nesse intervalo.
#In:
pd.DataFrame().assign(BootstrapMedians=boot_medians).plot(kind='hist', density=True, bins=np.arange(63000, 88000, 1000), ec='w', figsize=(10, 5), zorder=1)
plt.plot([left, right], [0, 0], color='gold', linewidth=12, label='95% confidence interval', zorder=2);
plt.scatter(population_median, 0.000004, color='blue', s=100, label='population median', zorder=3)
plt.legend()
plt.ylabel("Frequência");

- Nesse exemplo, note que nosso IC95% (representado pela linha dourada) contém o verdadeiro valor do parâmetro, isto é, a mediana populacional (representada pelo ponto azul).
- Note que isso nem sempre acontece, pois a amostra original pode não ser tão boa!
- Na prática, além de não saber o quão próxima a mediana amostral está da mediana populacional, em geral também não saberemos o quão boa a nossa amostra original realmente é.
- Discutiremos na próxima aula algumas maneiras de contornar esse problema.
- Finalmente, note pelo histograma acima que nesse exemplo a distribuição bootstrap não está centrada na mediana populacional (de \$78,136), mas sim na mediana amostral (\$76,237).
Teste Rápido ✅
Suponha que tenhamos calculado o seguinte IC95%:
#In:
print('Interval:', [left, right])
print('Width:', right - left)
Interval: [68469.0, 81253.5]
Width: 12784.5
onde Width acima representa a largura do IC, i.e. se $IC95\% = [y, x]$, sua largura é igual a $y - x$.
Agora, se ao invés de 95\% de confiança tivéssemos calculado um intervalo de 80% de confiança, isto é, um IC80\%, você acha que esse intervalo seria mais largo ou mais estreito do que o IC95%?
- A. Mais largo
- B. Mais estreito
- C. É impossível dizer
Para refletir
Na aula anterior, aprendemos a fazer afirmativas do tipo
Acreditamos que a mediana populacional está “próxima” da nossa mediana amostral, \$76,237.
Nessa aula, aprendemos a fazer afirmativas do tipo
Podemos dizer, com “95% de confiança”, que a mediana populacional está entre \$68,469 e \$81,253.50.
Restam ainda, porém, algumas dúvidas fundamentais:
- O que “95% de confiança” significa?
- Sobre o que exatamente estamos confiantes?
- Esse tipo de técnica é sempre aplicável?
Resumo e próxima aula
Resumo
- Com base em uma amostra, queremos inferir sobre um parâmetro populacional. Porém, como podemos calcular apenas uma estimativa com essa amostra, em geral não sabemos o quão precisa é essa estimativa.
- Para termos uma ideia do quão variável é nossa estimativa, idealmente coletaríamos mais amostras e calcularíamos nossa estatística em cada uma dessas amostras. Porém, na prática, amostrar em geral é caro, e logo usualmente temos disponível apenas uma amostra.
- Ideia principal: Sob certas condições, a amostra é distribuída de maneira bem similar à população da qual a amostra foi coletada. Dessa forma, podemos tratar a distribuição empírica da amostra como se fosse a distribuição populacional e produzir novas amostras reamostrando da amostra original.
- Cada nova amostra produzida dessa forma gera nos permite calcular uma nova estimativa. Com base em um conjunto dessas estimativas, podemos então ter uma noção da precisão/variabilidade da nossa estimativa original.
- O Bootstrap nos fornece uma maneira de gerarmos uma distribuição empírica de uma estatística, utilizando apenas uma única amostra original. Com base nessa distribuição bootstrap, podemos criar intervalos de $c$% confiança identificando os valores cujo intervalo contenha $c$% da distribuição entre si.
- Podemos assim quantificar a incerteza sobre nossas estimativas, e fazer afirmações do tipo “a média populacional está entre \$68,469 to \$81,253.50” ao invés de afirmar apenas que “a média populacional é aproximadamente \$76,237”.
Próxima aula
- Vamos definir e explicar melhor o nível de confiança, e aprender a interpretar de maneira mais precisa os intervalos de confiança.
- Vamos aprender a identificar estatísticas para as quais o bootstrap não funciona tão bem.
- Vamos aprender a quantificar a variabilidade em uma distribuição.