Análise do Número de Homicídios através de Índices Socioeconômicos no Brasil
Praticar a matéria fazendo uma análise não trivial
Sumário
- Análise do Número de Homicídios através de Índices Socioeconômicos no Brasil
- Introdução
- Imports
- Base de Dados
- Pré-processamento e Interpretação dos Dados
- Exploração de Dados
- Investigando Correlações
Introdução
Neste trabalho, utilizamos dados do Censo de 2010, abrangendo uma variedade de taxas e indicadores, como taxa de desemprego, PIB, população, GNI (Renda Nacional Bruta) e o número de homicídios (dados provenientes do SIM - Sistema de Informações sobre Mortalidade). Além disso, também dispomos de dados geográficos do país, divididos em estados e municípios, referentes ao ano de 2010.
O objetivo deste trabalho é analisar e interpretar esses dados de forma aprofundada, buscando identificar correlações entre os diferentes indicadores e o número de homicídios. Também buscamos compreender como essas relações se distribuem de acordo com as regiões do país, oferecendo uma visão mais clara das dinâmicas sociais e econômicas que impactam a violência em diferentes áreas.
Fontes:
Imports
#In:
import os
import scipy
import shutil
import numpy as np
import pandas as pd
import seaborn as sns
from tqdm import tqdm
import geopandas as gpd
import statsmodels.api as sm
import ipywidgets as widgets
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
from IPython.display import display, clear_output
Base de Dados
As bases de dados disponibilizadas estão no arquivo data.zip, que está organizado em duas pastas principais: dados_geograficos e indicadores.
Na pasta dados_geograficos, encontram-se os arquivos geográficos necessários para a plotagem dos mapas dos estados brasileiros. Cada estado possui uma subpasta nomeada no padrão XX_municipios, onde XX é a sigla do estado (por exemplo: al_municipios, mg_municipios, sp_municipios). Dentro de cada subpasta estão os arquivos .shp, .shx e .dbf, que descrevem os polígonos dos municípios e permitem a plotagem dos mapas com a biblioteca GeoPandas.
Já na pasta indicadores, estão os dados já “limpos”, que incluem os arquivos ibge_desemprego, ibge_pib, ibge_populacao e ibge_sim. Cada um desses arquivos contém um ID único para os municípios, seguido pelos respectivos dados de cada indicador.
A seguir, vamos explorar esses dados para entender como trabalhar com eles de forma eficiente.
#In:
!wget "https://github.com/flaviovdf/fcd/raw/refs/heads/main/projeto/data_20251/real_data_fcd.zip" -P ./
caminho_zip = './real_data_fcd.zip'
caminho_destino = './data_fcd/' # Pasta onde os arquivos serão extraídos
# Se já existe a pasta, apaga ela primeiro (para garantir substituição completa)
if os.path.exists(caminho_destino):
shutil.rmtree(caminho_destino)
# Cria a pasta destino novamente
os.makedirs(caminho_destino, exist_ok=True)
# Descompacta mantendo estrutura
!unzip -q {caminho_zip} -d {caminho_destino}
!rm {caminho_zip}
Pré-processamento e Interpretação dos Dados
Tarefa 1: Entendendo, organizando e pré-processando os dados
Primeiro vamos pré-processar as tabelas. Primeira coisa a ser feita é trocar as vírgulas por pontos nos arquivos de indicadores.
#In:
# Faz a substituição de vírgulas por pontos nos arquivos corretos
!sed -i 's/,/./g' './data_fcd/indicadores/ibge_desemprego.csv'
!sed -i 's/,/./g' './data_fcd/indicadores/ibge_populacao.csv'
!sed -i 's/,/./g' './data_fcd/indicadores/ibge_pib.csv'
!sed -i 's/,/./g' './data_fcd/indicadores/ibge_sim.csv'
Neste processo, vamos criar um dicionário chamado indicadores, que armazenará uma lista de DataFrames correspondentes a diferentes indicadores. Para garantir que os IDs dos indicadores coincidam com os IDs dos dados geográficos, é necessário realizar uma padronização. A primeira coluna dos arquivos de indicadores contém dados no formato “110001 ALTA FLORESTA D’OESTE”, onde o ID numérico do município é seguido pelo nome do município. Vamos separar essa coluna para extrair apenas o código numérico do ID.
Além disso, é essencial assegurar que todos os IDs tenham exatamente 6 dígitos. Enquanto os IDs dos indicadores já seguem esse padrão, os IDs dos dados geográficos possuem 7 dígitos. No entanto, podemos desconsiderar o último dígito dos IDs geográficos, permitindo que eles fiquem compatíveis com os IDs dos indicadores. Esse ajuste é possível porque os primeiros 6 dígitos do ID representam o código do município, sendo que os dois primeiros dígitos correspondem ao DDD do estado.
Com essa padronização, será possível realizar a correspondência correta entre os indicadores e os dados geográficos dos municípios, garantindo a integridade e precisão da análise.
#In:
indicadores = {}
for data in os.listdir("../projeto/data_20251/indicadores/"):
path = f"../projeto/data_20251/indicadores/{data}"
if os.path.isfile(path) and data.endswith('.csv'):
nome_indicador = os.path.splitext(data)[0]
df = pd.read_csv(path, sep=';')
# Separar a coluna 'Municipio' em ID (6 dígitos) e Nome do município
df[['ID', 'Nome_Mun']] = df['Municipio'].str.extract(r'(\d{6})\s+(.*)', expand=True)
# Garantir que o ID seja string
df['ID'] = df['ID'].astype(str)
# Remover a coluna antiga 'Municipio' já que agora temos ID e Nome separados
df.drop(columns=['Municipio'], inplace=True)
# Salvar o dataframe processado
indicadores[nome_indicador] = df
print(f"Indicador: {nome_indicador} -> Colunas: {df.columns.tolist()[:5]}")
# Exemplo pra ver se está certo
print("Exemplo do indicador ibge_desemprego:")
print(indicadores['ibge_desemprego'].head())
Exploração de Dados
Aqui vamos fazer um breve exploração dos dados, vamos ver exemplos de como plotar o mapa de cada estado de acordo com algum dos indicadores que salvamos em nosso dicionário anterioremente e como unir os estados para plotar o mapa do Brasil.
Exemplo — Indicadores por Estado e Mapa do Brasil Completo
Nesta seção, vamos exemplificar como realizar a plotagem de mapas que ajudam na visualização dos dados e nas análises futuras. Visualizar os mapas é essencial porque permite identificar padrões, discrepâncias e validar se os indicadores e as análises realmente fazem sentido quando distribuídos geograficamente.
Por que a visualização é importante?
- Permite detectar padrões regionais (ex.: desemprego maior em determinadas áreas).
- Ajuda a verificar a consistência dos dados.
- Facilita a comunicação dos resultados com outras pessoas de forma visual e intuitiva.
Estrutura do Código
Para facilitar a plotagem dos mapas, o código foi organizado com algumas funções e dicionários auxiliares:
Função
sigla_to_cod:
Converte a sigla do estado (ex.:'mg') para o código numérico usado pelos shapefiles.Dicionários
coluna_por_indicadorenomes_bonitos:
Relacionam os nomes técnicos dos indicadores com nomes mais amigáveis para exibição no mapa.
Exemplo:'ibge_pib'é exibido como'PIB'.Lista
siglas_estados:
Lista com todas as siglas dos estados brasileiros para facilitar o carregamento, vemos que as siglas são mapeadas para o DDD de cada estado (como vimos no tópico anterior). —
#In:
# Função auxiliar para pegar código da UF
def sigla_to_cod(sigla):
sigla = sigla.lower()
uf_codigos = {
'ro': '11', 'ac': '12', 'am': '13', 'rr': '14', 'pa': '15', 'ap': '16', 'to': '17',
'ma': '21', 'pi': '22', 'ce': '23', 'rn': '24', 'pb': '25', 'pe': '26', 'al': '27', 'se': '28', 'ba': '29',
'mg': '31', 'es': '32', 'rj': '33', 'sp': '35',
'pr': '41', 'sc': '42', 'rs': '43',
'ms': '50', 'mt': '51', 'go': '52', 'df': '53'
}
return uf_codigos[sigla]
# Dicionário com colunas e nomes bonitos
coluna_por_indicador = {
'ibge_sim': 'Obitos',
'ibge_populacao': 'Populacao_residente',
'ibge_desemprego': 'Taxa_de_desemprego.',
'ibge_pib': 'Produto_interno_bruto_(PIB).'
}
nomes_bonitos = {
'ibge_pib': 'PIB',
'ibge_sim': 'Óbitos',
'ibge_populacao': 'População',
'ibge_desemprego': 'Desemprego (%)'
}
siglas_estados = [
'ac', 'al', 'am', 'ap', 'ba', 'ce', 'df', 'es', 'go',
'ma', 'mg', 'ms', 'mt', 'pa', 'pb', 'pe', 'pi', 'pr',
'rj', 'rn', 'ro', 'rr', 'rs', 'sc', 'se', 'sp', 'to'
]
Funções Principais
carregar_estado_mapa(sigla_estado, nome_indicador)
Carrega o shapefile do estado selecionado e junta (faz merge) com os dados do indicador desejado.
Essa função:- Lê os arquivos de geodados (shapefiles,
.shp). - Filtra os dados do indicador para os municípios do estado.
- Fazemos o merge pelo
IDe pelocod6, porém como vimos o ID são apenas 6 dígitos e o cod6 são 7, mas dos quais apenas os 6 primeiros são necessários. - Retorna um GeoDataFrame pronto para ser plotado.
- Lê os arquivos de geodados (shapefiles,
plot_estado_indicador(sigla_estado, nome_indicador)
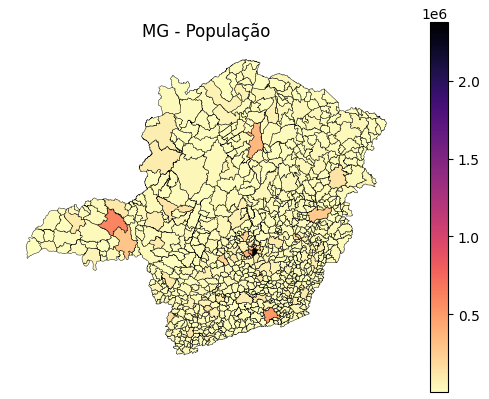
Plota o mapa com os municípios do estado coloridos de acordo com o valor do indicador.
Exemplo: Mapa de Minas Gerais colorido pela taxa de desemprego.plot_brasil_indicador(nome_indicador)
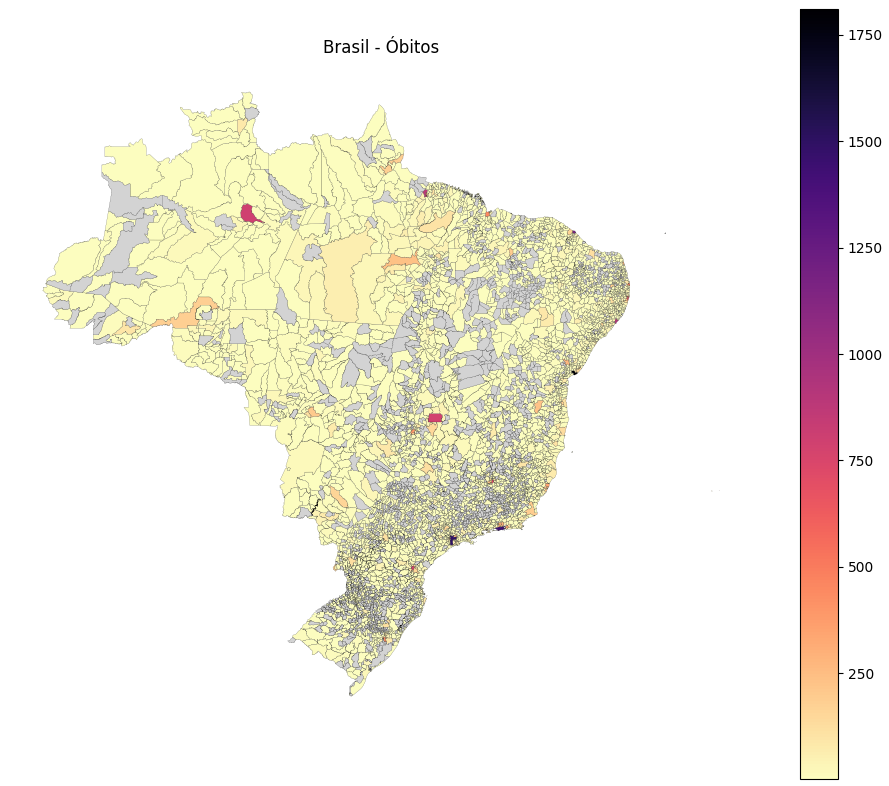
Plota o mapa do Brasil inteiro, juntando os mapas de todos os estados.
Ideal para uma visualização nacional do indicador escolhido, como o PIB ou número de óbitos. —
#In:
# Função para carregar o mapa do estado com indicador
def carregar_estado_mapa(sigla_estado, nome_indicador):
coluna_indicador = coluna_por_indicador[nome_indicador]
df_indicador = indicadores[nome_indicador]
pasta_estado = f'../projeto/data_20251/dados_geograficos/{sigla_estado}_municipios/'
arquivos_shp = [f for f in os.listdir(pasta_estado) if f.endswith('.shp')]
if not arquivos_shp:
print(f"Nenhum shapefile encontrado para {sigla_estado.upper()}")
return None
arquivo_shp = arquivos_shp[0]
caminho_shp = os.path.join(pasta_estado, arquivo_shp)
mapa = gpd.read_file(caminho_shp)
mapa['cod6'] = mapa['CD_GEOCODM'].str[:6]
df_indicador_filtered = df_indicador[df_indicador['ID'].isin(mapa['cod6'])]
mapa_indicador = mapa.merge(df_indicador_filtered, left_on='cod6', right_on='ID', how='left')
return mapa_indicador
# Função para plotar o estado
def plot_estado_indicador(sigla_estado, nome_indicador):
mapa_indicador = carregar_estado_mapa(sigla_estado, nome_indicador)
if mapa_indicador is None:
return
coluna_indicador = coluna_por_indicador[nome_indicador]
plt.figure(figsize=(8, 6))
mapa_indicador.plot(
column=coluna_indicador,
cmap='magma_r',
legend=True,
missing_kwds={"color": "lightgrey", "label": "Sem dado"},
edgecolor='black',
linewidth=0.3
)
plt.title(f"{sigla_estado.upper()} - {nomes_bonitos[nome_indicador]}")
plt.axis('off')
plt.show()
# Função para plotar o Brasil inteiro
brasil_mapa = None
def plot_brasil_indicador(nome_indicador):
global brasil_mapa
gdfs_estados = []
coluna_indicador = coluna_por_indicador[nome_indicador]
df_indicador = indicadores[nome_indicador]
for sigla in tqdm(siglas_estados, desc="Carregando estados para mapa Brasil"):
mapa_indicador = carregar_estado_mapa(sigla, nome_indicador)
if mapa_indicador is not None:
gdfs_estados.append(mapa_indicador)
brasil_mapa = pd.concat(gdfs_estados, ignore_index=True)
fig, ax = plt.subplots(figsize=(12, 10))
brasil_mapa.plot(
column=coluna_indicador,
cmap='magma_r',
legend=True,
edgecolor="k",
linewidth=0.1,
missing_kwds={"color": "lightgrey", "label": "Sem dado"},
ax=ax
)
ax.set_title(f"Brasil - {nomes_bonitos[nome_indicador]}")
ax.axis('off')
plt.show()
Widgets para Visualização Interativa
Para tornar a visualização dos mapas mais interativa, utilizamos widgets do ipywidgets. Com eles, conseguimos selecionar de forma dinâmica qual estado e qual indicador queremos visualizar no mapa, sem precisar alterar o código manualmente.
- Estado: um menu dropdown para escolher a sigla do estado.
- Indicador: outro dropdown para selecionar o indicador (como população, PIB ou desemprego).
Sempre que fazemos uma nova seleção, o mapa é atualizado automaticamente. Isso torna a exploração dos dados mais rápida e interativa!
OBS: isso é apenas para exemplificar, não é necessário usar esse tipode visualização, mas sintam se a vontade para explorar!
#In:
# Widgets para Estados
estado_widget = widgets.Dropdown(
options=siglas_estados,
value='mg',
description='Estado:',
)
indicador_widget = widgets.Dropdown(
options=list(coluna_por_indicador.keys()),
value='ibge_populacao',
description='Indicador:',
)
ui_estado = widgets.HBox([estado_widget, indicador_widget])
out_estado = widgets.interactive_output(
plot_estado_indicador,
{'sigla_estado': estado_widget, 'nome_indicador': indicador_widget}
)
display(ui_estado, out_estado)
#In:
# Widget para Brasil
indicador_brasil_widget = widgets.Dropdown(
options=list(coluna_por_indicador.keys()),
value='ibge_populacao',
description='Indicador:',
)
ui_brasil = widgets.HBox([indicador_brasil_widget])
out_brasil = widgets.interactive_output(
plot_brasil_indicador,
{'nome_indicador': indicador_brasil_widget}
)
display(ui_brasil, out_brasil)
Tarefa 2: Gráficos de Barra para os Indicadores
Nesta tarefa, vamos explorar os indicadores de forma visual usando gráficos de barra e mapas.
Escolha um indicador para fazer as visualizações abaixo.
Se quiser, sinta-se livre para repetir os passos para os outros indicadores também!
(A) Gráficos por Estado:
Faça um gráfico de barra mostrando o valor do indicador escolhido para cada estado do Brasil.- (B) TOP 10 Municípios de um Estado:
Escolha um estado e faça dois gráficos de barra:- Um com os 10 municípios com os maiores valores do indicador.
- Outro com os 10 municípios com os menores valores.
- (C) Mapa do Estado Escolhido:
Plote o mapa do estado escolhido, aplicando um esquema de cores caprichado para destacar melhor as diferenças entre os municípios.- DICA: use a função definida anteriormente!
Tarefa 3: Comparando Capitais
Crie gráficos de barra para comparar os quatro indicadores entre as capitais dos estados.
- Dica: Filtre os dados referentes apenas às capitais e utilize um
mergepara reunir os indicadores em um único DataFrame. - Dica: Ordene os valores nos gráficos para facilitar a visualização e experimente diferentes escalas para melhorar a comparação entre os indicadores.
Tarefa 4: Discretizando Dados no Mapa
Utilize o indicador ibge_sim (óbitos) para plotar o mapa dos municípios de um estado brasileiro. Aplique uma transformação nos dados, como uma escala logarítmica, para melhorar a visualização e discretize os valores em 4 ou 5 faixas de cores que destaquem de forma clara as diferenças no número de óbitos entre os municípios.
- Dica: Escolha faixas de discretização que realmente evidenciem os contrastes entre municípios com poucos e muitos óbitos.
- Extra: Dê um destaque visual na capital do estado escolhido, usando, por exemplo, uma borda ou uma cor especial.
Além do gráfico, explique brevemente como foi feita a escolha das faixas de discretização e por que ela facilita a interpretação do mapa.
Os municípios foram divididos em 5 faixas (ou 5 categorias).
Os valores da coluna ‘categoria’ vão de 0 até 4:
0 → faixa com menos óbitos.
4 → faixa com mais óbitos.
Então:
categoria Significado 0 Municípios com menos óbitos 1 Pouco mais que 0 2 Faixa intermediária 3 Já com número alto 4 Os que têm mais óbitos
Tarefa 5: Análise dos 10 municípios com maior indicador ibge_sim
Nesta tarefa, você deverá:
- Identificar os 10 municípios com o maior valor do indicador
ibge_sim. - Criar um gráfico de barras para visualizar esses municípios e seus respectivos valores do indicador.
- Ao lado do gráfico, exibir o mapa do Brasil destacando esses municípios.
- Dica: Utilize o mapa do Brasil já criado no exemplo anterior para destacar os municípios selecionados no gráfico de barras.
Boa sorte!
Investigando Correlações
Tarefa 6: vamos brincar de regressão
(A)
Inicialmente, faça um gráfico de dispersão onde o eixo X é o PIB, e o Y é o número de óbitos.
Sua base de dados deve ser todos os munícipios, de 5 estados diferentes. Nosso objetivo é pegar 1 estado de cada região brasileira.
- Para facilitar um pouco, vamos usar Espírito Santo (es), Pernambuco (pe), Goiás (go), Acre (ac) e Santa Cataria (sc).
Isso totaliza 5 gráficos, cada ponto no gráfico vai corresponder a um bairro, e as cores representam o estado referente.
PS: Se você preferir, pode fazer 5 plots separados. Particularmente, pode ser mais interessante um plot único.
(B) Agora, repita o experimento anterior, só que altere o eixo X para ser a População do município.
(C) Agora, depois de observar as os gráficos, vamos começar a fazer as regressões lineares. 🛫
Vamos usar, para o nosso modelo, apenas os 5 Estados separados anteriormente.
Nossas 2 primeiras regressões devem ser uma regressão linear simples, onde a variável predita Y é óbito e X é a População e outra regressão linear simples, apenas alterando o X para PIB.
PS: Para isso, você deve usar a biblioteca statsmodel.api, que vai facilitar (e muito) nossas vidas.
import statsmodels.api as sm
Fique a vontade para pesquisar sobre a biblioteca (você deveria dar uma olhadinha em algumas coisas 😇), mas aqui vai algumas funções interessantes.
model = sm.OLS(y, X) # use para criar um modelo. (de uma olhada nas funções disponiveis num "objeto" OLS.)
sm.add_constant(X) # adiciona um vetor de 1's.
res = model.fit() # executa a regressão linear e obtem os coeficientes
print(res.summary()) # te entrega um resumo super supimpa sobre a regressão!
PS2: Não se esqueça de Z-Normalizar os dados😊
(D) Faça uma comparação da qualidade dos 2 modelos. Além disso, você consegue perceber algo muito estranho com a regressão do PIB? Você acha que o resultado obtido é contrário ao que você espera na realidade, ao usar o PIB para prever os óbitos?
- Dica: Será que existe alguma correlação entre PIB e População?
(E) Faça uma regressão linear, mas agora, essa será uma regressão múltipla. Utilize como variáveis preditoras tanto o PIB quanto a População. Você consegue perceber algo estranho com uma das duas variáveis, em relação aos sumários anteriores?
- Dica: Verifique os intervalos de confiança e os pesos $W_{pib}$ e $W_{pop}$ atrelados a variáveis, e tente pensar na equação intuitivamente. Será que faz sentido com o que você espera na realidade?
(F) EXTRA: Tente adicionar a taxa de desemprego ou realizar modificações nas variáveis de predição, tentando obter alguma melhora no modelo. As modificações podem ser utilizar escalas diferentes, como np.log10 ou np.log2 nos dados, fazendo uma reescala, ou adicionar novas features, como PIB_per_capita ou taxa_de_desemprego_per_capita.
O objetivo da questão é que você seja criativo e também entender que as vezes a regressão linear é limitada; não tente criar a roda, mas também não gaste 5 minutos pensando. 🧙